秒级执行,前面加上sleep就可以解决了
sleep 5;/path/to/script
秒级执行,前面加上sleep就可以解决了
sleep 5;/path/to/script
(function (exports, require, module, __filename, __dirname) { import "core-js/modules/es6.regexp.constructor";
SyntaxError: Unexpected string
at new Script (vm.js:80:7)
at createScript (vm.js:274:10)
at Object.runInThisContext (vm.js:326:10)
报错原因1:不识别es6语法
解决方法:npm install core-js@2
报错原因2:vue隐藏文件没复制过来
解决方法:复制过来隐藏文件解决
1.从CURL中获取响应头
$oCurl = curl_init();
// 设置请求头, 有时候需要,有时候不用,看请求网址是否有对应的要求
$header[] = "Content-type: application/x-www-form-urlencoded";
$user_agent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36";
curl_setopt($oCurl, CURLOPT_URL, $sUrl);
curl_setopt($oCurl, CURLOPT_HTTPHEADER,$header);
// 返回 response_header, 该选项非常重要,如果不为 true, 只会获得响应的正文
curl_setopt($oCurl, CURLOPT_HEADER, true);
// 是否不需要响应的正文,为了节省带宽及时间,在只需要响应头的情况下可以不要正文
curl_setopt($oCurl, CURLOPT_NOBODY, true);
// 使用上面定义的 ua
curl_setopt($oCurl, CURLOPT_USERAGENT,$user_agent);
curl_setopt($oCurl, CURLOPT_RETURNTRANSFER, 1 );
// 不用 POST 方式请求, 意思就是通过 GET 请求
curl_setopt($oCurl, CURLOPT_POST, false);
$sContent = curl_exec($oCurl);
// 获得响应结果里的:头大小
$headerSize = curl_getinfo($oCurl, CURLINFO_HEADER_SIZE);
// 根据头大小去获取头信息内容
$header = substr($sContent, 0, $headerSize);
curl_close($oCurl);
2.从curl中获取请求头
$oCurl = curl_init(); curl_setopt($oCurl, CURLOPT_URL, "https://117.28.240.235:8002/ipcc/agent/login"); curl_setopt($oCurl, CURLOPT_HTTPHEADER, $header); //关闭https验证 curl_setopt($oCurl, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($oCurl, CURLOPT_SSL_VERIFYHOST, false); //至关重要,CURLINFO_HEADER_OUT选项可以拿到请求头信息 curl_setopt($oCurl, CURLINFO_HEADER_OUT, TRUE); curl_setopt($oCurl, CURLOPT_RETURNTRANSFER, 1); curl_setopt($oCurl, CURLOPT_POST, 1); curl_setopt($oCurl, CURLOPT_POSTFIELDS, $bodystr); $sContent = curl_exec($oCurl); //通过curl_getinfo()可以得到请求头的信息 $a=curl_getinfo($oCurl);
laravel post请求301原因
常用的一共有4个方法,如下:
1.使用locate()方法
普通用法:
SELECT`column`from`table`wherelocate('keyword',`condition`)>0
类似于java的indexOf();
不过locate()只要找到返回的结果都大于0(即使是查询的内容就是最开始部分),没有查找到才返回0;
指定起始位置:
SELECT LOCATE('bar','foobarbar',5);(从foobarbar的第五个位置开始查找)
2.使用instr()函数(据说是locate()的别名函数)
SELECT `column` from `table` where instr(`condition`,‘keyword')>0
唯一不同的是查询内容的位置不同
3.使用position()方法,(据说也是locate()方法的别名函数,功能一样)
SELECT `column` from `table` where position(‘keyword' IN `condition`)
不过它不再是通过返回值来判断,而是使用关键字in
4.使用find_in_set()函数
如:find_in_set(str,strlist),strlist必须要是以逗号分隔的字符串
如果字符串str是在的strlist组成的N子串的字符串列表,返回值的范围为1到N
SQL>SELECTFIND_IN_SET('b','a,b,c,d');
---------------------------------------------------------+
|SELECTFIND_IN_SET('b','a,b,c,d')|
---------------------------------------------------------+
|2|
---------------------------------------------------------+
1rowinset(0.00sec)
find_in_set()比较特殊,但它们都是返回要查找的子字符串在指定字符串中的位置。
速度上前3个要比用like稍快一点。(不过这四个函数都不能使用索引)
下面为再为大家介绍一下Mysql中Like的使用方法
MySQL的like语句中的通配符:百分号、下划线和escape
%:表示任意个或多个字符。可匹配任意类型和长度的字符。
Sql代码
select * from user where username like '%huxiao';
select * from user where username like 'huxiao%';
select * from user where username like '%huxiao%';
另外,如果需要找出u_name中既有“三”又有“猫”的记录,请使用and条件
SELECT * FROM [user] WHERE u_name LIKE ‘%三%' AND u_name LIKE ‘%猫%'
若使用 SELECT * FROM [user] WHERE u_name LIKE ‘%三%猫%'
虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”。
_:表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句:(可以代表一个中文字符)
Sql代码
select * from user where username like '_';
select * from user where username like 'huxia_';
select * from user where username like 'h_xiao';
如果我就真的要查%或者_,怎么办呢?使用escape,转义字符后面的%或_就不作为通配符了,注意前面没有转义字符的%和_仍然起通配符作用
Sql代码
select username from gg_user where username like '%xiao/_%' escape '/';
select username from gg_user where username like '%xiao/%%' escape '/';
MySQL 通配符
SQL的模式匹配允许你使用“_”匹配任何单个字符,而“%”匹配任意数目字符(包括零个字符)。在 MySQL中,SQL的模式缺省是忽略大小写的。下面显示一些例子。
注意在你使用SQL模式时,你不能使用=或!=;而使用LIKE或NOT LIKE比较操作符。
为了找出以“b”开头的名字:
mysql> SELECT * FROM pet WHERE name LIKE "b%"; +--------+--------+---------+------+------------+------------+ | name | owner | species | sex | birth | death | +--------+--------+---------+------+------------+------------+ | Buffy | Harold | dog | f | 1989-05-13 | NULL | | Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 | +--------+--------+---------+------+------------+------------+
为了找出以“fy”结尾的名字:
mysql> SELECT * FROM pet WHERE name LIKE "%fy"; +--------+--------+---------+------+------------+-------+ | name | owner | species | sex | birth | death | +--------+--------+---------+------+------------+-------+ | Fluffy | Harold | cat | f | 1993-02-04 | NULL | | Buffy | Harold | dog | f | 1989-05-13 | NULL | +--------+--------+---------+------+------------+-------+
为了找出包含一个“w”的名字:
mysql> SELECT * FROM pet WHERE name LIKE "%w%"; +----------+-------+---------+------+------------+------------+ | name | owner | species | sex | birth | death | +----------+-------+---------+------+------------+------------+ | Claws | Gwen | cat | m | 1994-03-17 | NULL | | Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 | | Whistler | Gwen | bird | NULL | 1997-12-09 | NULL | +----------+-------+---------+------+------------+------------+
为了找出包含正好5个字符的名字,使用“_”模式字符:
mysql> SELECT * FROM pet WHERE name LIKE "_____"; +-------+--------+---------+------+------------+-------+ | name | owner | species | sex | birth | death | +-------+--------+---------+------+------------+-------+ | Claws | Gwen | cat | m | 1994-03-17 | NULL | | Buffy | Harold | dog | f | 1989-05-13 | NULL | +-------+--------+---------+------+------------+-------+
由MySQL提供的模式匹配的其他类型是使用扩展正则表达式。当你对这类模式进行匹配测试时,使用REGEXP和NOT REGEXP操作符(或RLIKE和NOT RLIKE,它们是同义词)。
扩展正则表达式的一些字符是:
“.”匹配任何单个的字符。
一个字符类“[…]”匹配在方括号内的任何字符。
例如,“[abc]”匹配“a”、“b”或“c”。为了命名字符的一个范围,使用一个“-”。“[a-z]” 匹配任何小写字母,而“[0-9]”匹配任何数字。
“ * ”匹配零个或多个在它前面的东西。
例如,“x*”匹配任何数量的“x”字符,“[0-9]*”匹配的任何数量的数字,而“.*”匹配任何数量的任何东西。
正则表达式是区分大小写的,但是如果你希望,你能使用一个字符类匹配两种写法。
例如,“[aA]”匹配小写或大写的“a”而“[a-zA-Z]”匹配两种写法的任何字母。
如果它出现在被测试值的任何地方,模式就匹配(只要他们匹配整个值,SQL模式匹配)。
为了定位一个模式以便它必须匹配被测试值的开始或结尾,在模式开始处使用“^”或在模式的结尾用“$”。
为了说明扩展正则表达式如何工作,上面所示的LIKE查询在下面使用REGEXP重写:
为了找出以“b”开头的名字,使用“^”匹配名字的开始并且“[bB]”匹配小写或大写的“b”:
mysql> SELECT * FROM pet WHERE name REGEXP "^[bB]"; +--------+--------+---------+------+------------+------------+ | name | owner | species | sex | birth | death | +--------+--------+---------+------+------------+------------+ | Buffy | Harold | dog | f | 1989-05-13 | NULL | | Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 | +--------+--------+---------+------+------------+------------+
mysql> SELECT * FROM pet WHERE name REGEXP "fy$"; +--------+--------+---------+------+------------+-------+ | name | owner | species | sex | birth | death | +--------+--------+---------+------+------------+-------+ | Fluffy | Harold | cat | f | 1993-02-04 | NULL | | Buffy | Harold | dog | f | 1989-05-13 | NULL | +--------+--------+---------+------+------------+-------+
为了找出包含一个“w”的名字,使用“[wW]”匹配小写或大写的“w”:
mysql> SELECT * FROM pet WHERE name REGEXP "[wW]"; +----------+-------+---------+------+------------+------------+ | name | owner | species | sex | birth | death | +----------+-------+---------+------+------------+------------+ | Claws | Gwen | cat | m | 1994-03-17 | NULL | | Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 | | Whistler | Gwen | bird | NULL | 1997-12-09 | NULL | +----------+-------+---------+------+------------+------------+
既然如果一个正规表达式出现在值的任何地方,其模式匹配了,就不必再先前的查询中在模式的两方面放置一个通配符以使得它匹配整个值,就像如果你使用了一个SQL模式那样。
为了找出包含正好5个字符的名字,使用“^”和“$”匹配名字的开始和结尾,和5个“.”实例在两者之间:
mysql> SELECT * FROM pet WHERE name REGEXP "^.....$"; +-------+--------+---------+------+------------+-------+ | name | owner | species | sex | birth | death | +-------+--------+---------+------+------------+-------+ | Claws | Gwen | cat | m | 1994-03-17 | NULL | | Buffy | Harold | dog | f | 1989-05-13 | NULL | +-------+--------+---------+------+------------+-------+
你也可以使用“{n}”“重复n次”操作符重写先前的查询:
mysql> SELECT * FROM pet WHERE name REGEXP "^.{5}$";
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
以上是Mysql模糊搜索方法Like的使用方法,与前locate instr position这三个内置函数相比性能上要慢些,无论哪种模糊搜索在查询时都会消耗大量服务器资源所以在实际工作中我们应尽量少用模糊搜索
MYSQL BENCHMARK函数是最重要的函数之一,下文对该函数的使用进行了详尽的分析,如果您对此感兴趣的话,不妨一看。
下文为您介绍的是MYSQL BENCHMARK函数的语法,及一些MYSQL BENCHMARK函数相关问题的测试,供您参考学习。
报告的时间是客户端的经过时间,不是在服务器端的CPU时间。执行BENCHMARK()若干次可能是明智的,并且注意服务器机器的负载有多重来解释结果。
——————————————————————————–
只要我们把参数count 设置大点,那么那执行的时间就会变长。下面我们看看在mysql里执行的效果:
由此可以看出使用benchmark执行500000次的时间明显比正常执行时间延长了。
以上就是MYSQL BENCHMARK函数的使用介绍。
适用于前后台路径不一致问题
dirname(__FILE__)
<?php
// 创建 cURL 共享句柄,并设置共享 cookie 数据
$sh = curl_share_init();
curl_share_setopt($sh, CURLSHOPT_SHARE, CURL_LOCK_DATA_COOKIE);
// 初始化第一个 cURL 句柄,并将它设置到共享句柄
$ch1 = curl_init("http://example.com/");
curl_setopt($ch1, CURLOPT_SHARE, $sh);
// 执行第一个 cURL 句柄
curl_exec($ch1);
// 初始化第二个 cURL 句柄,并将它设置到共享句柄
$ch2 = curl_init("http://php.net/");
curl_setopt($ch2, CURLOPT_SHARE, $sh);
// 执行第二个 cURL 句柄
// all cookies from $ch1 handle are shared with $ch2 handle
curl_exec($ch2);
// 关闭 cURL 共享句柄
curl_share_close($sh);
// 关闭 cURL 共享句柄
curl_close($ch1);
curl_close($ch2);
?>
private function export_csv($filename,$data) {
header("Content-type:text/csv");
header("Content-Disposition:attachment;filename=".$filename);
header('Cache-Control:must-revalidate,post-check=0,pre-check=0');
header('Expires:0');
header('Pragma:public');
echo chr(239).chr(187).chr(191);
echo $data;
}
在项目的根目录下执行npm install react-native-icons@latest --save,下载完成后可以在node_modules目录下看到该插件:

目前只支持iOS,所以只有xcode的配置:
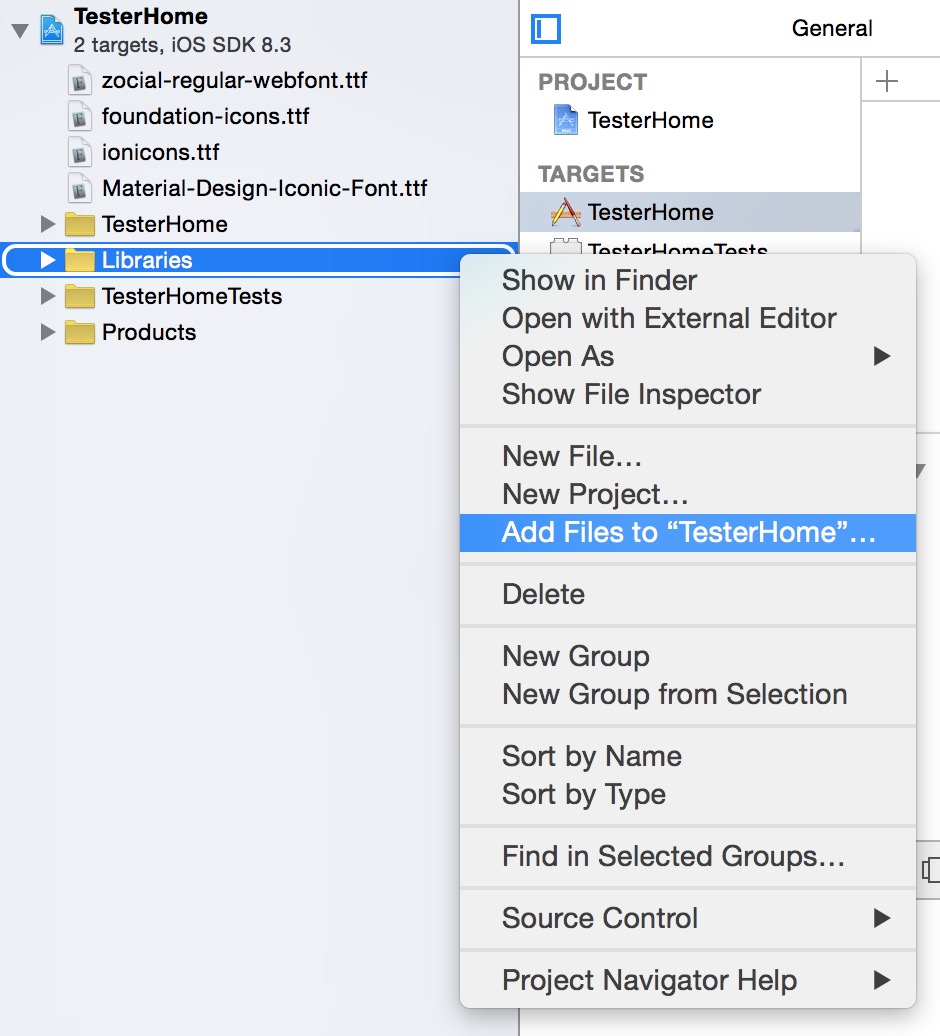
1.项目Libraries上右键:
添加项目根目录下的node_modules/react-native-icons/ios/ReactNativeIcons.xcodeproj
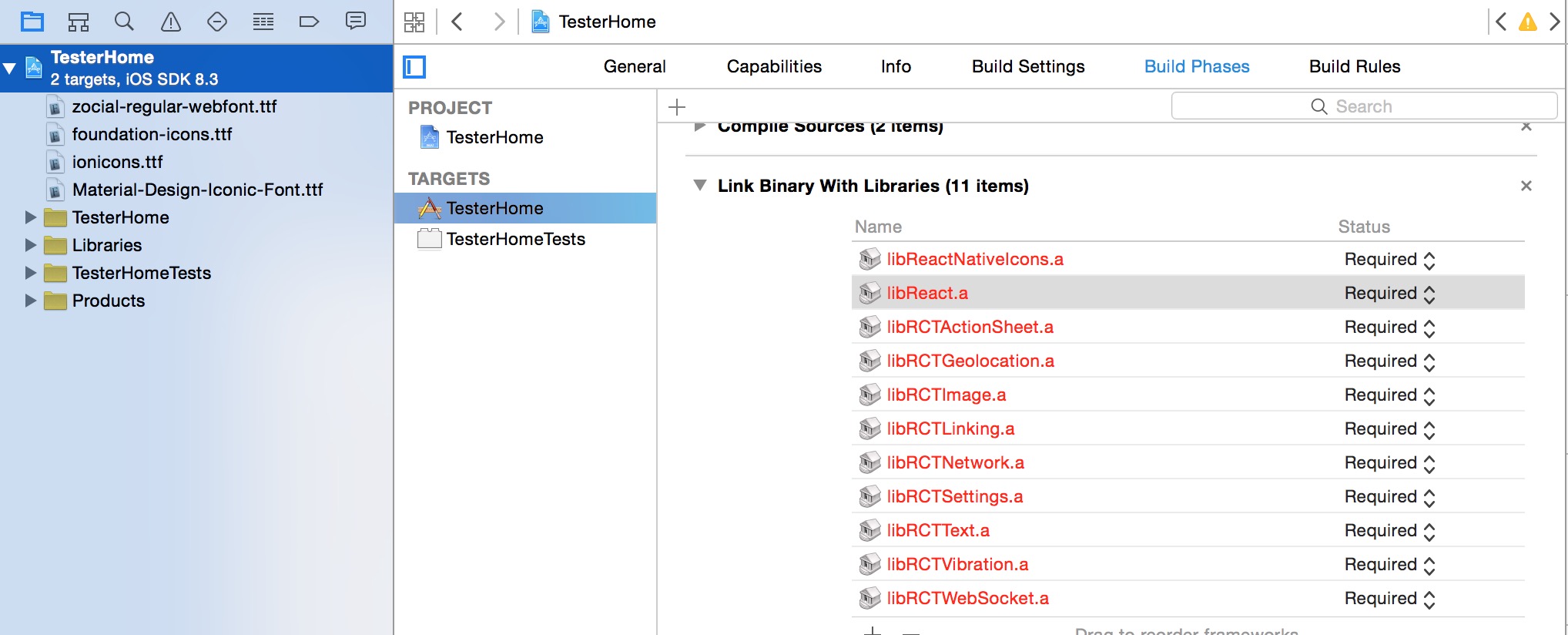
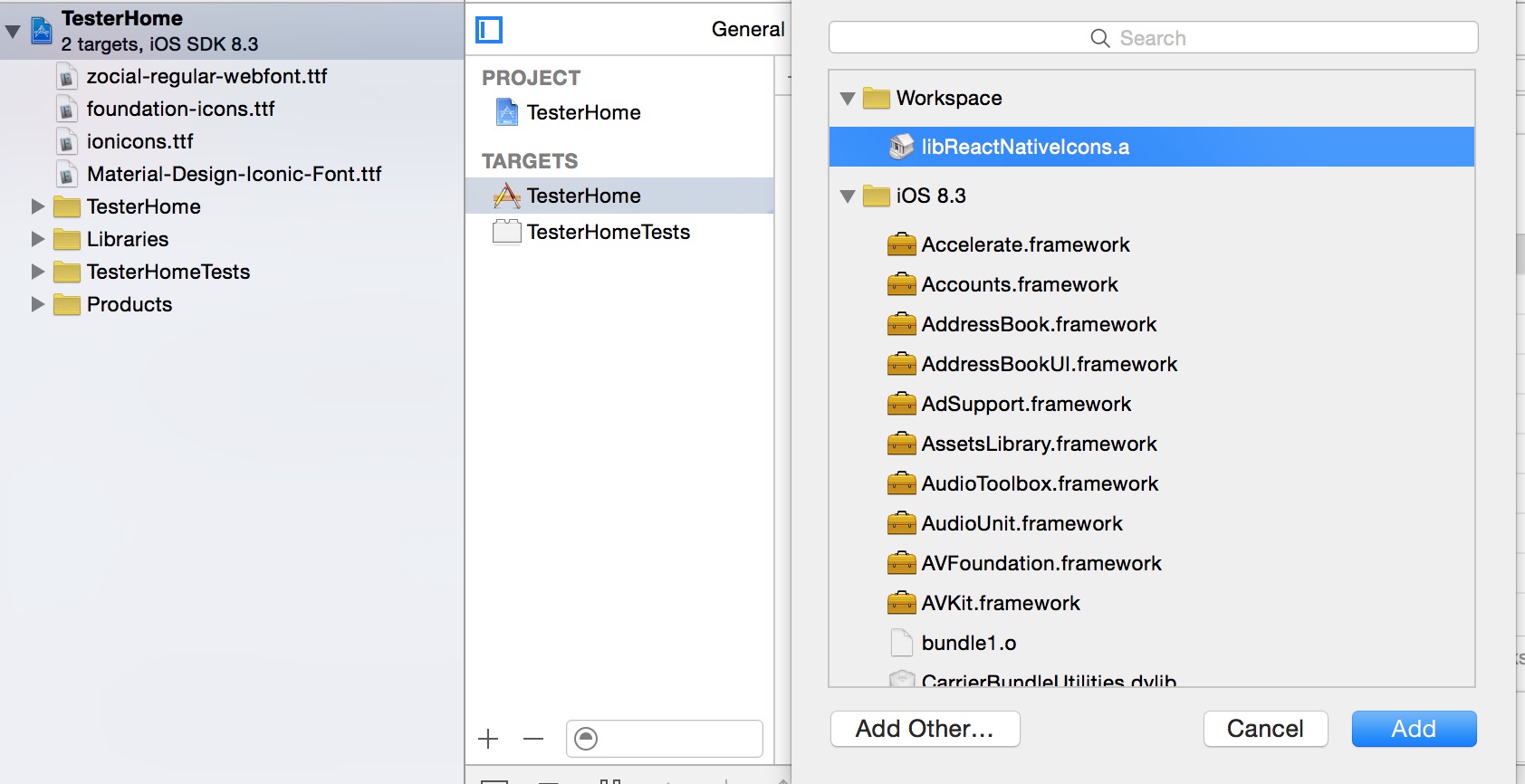
2.引用libReactNativeIcons.a:
单机项目,在右面的面板中选择Build Phases下的Link Binary With Libraries,点击+号添加库:
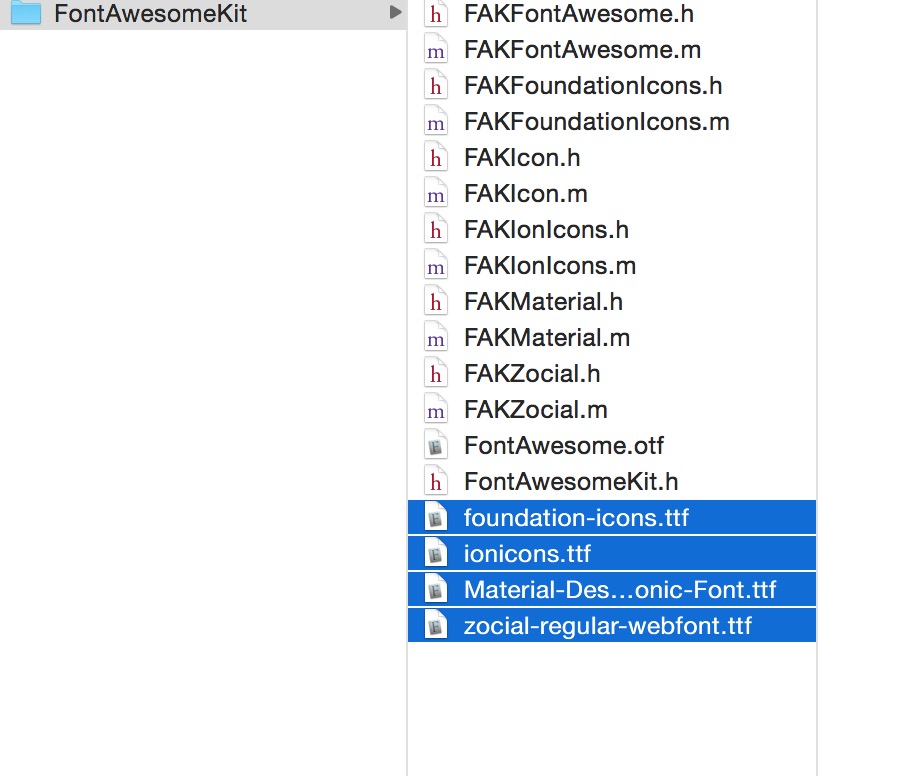
3.添加ttf文件:
这个地方要注意,github上直说了引用node_modules/react-native-icons/ios/ReactNativeIcons/Libraries/FontAwesomeKit文件夹,但是主要的还是4个ttf文件:
单机项目,在右面的面板中选择Build Phases下Copy Bundle Resources选择+号,在出现的文件选择器中点击Add Other...,定位到node_modules/react-native-icons/ios/ReactNativeIcons/Libraries/FontAwesomeKit目录下,把所有的ttf文件和otf都勾选上:


要想使用react-native-icons,需要在代码中添加如下语句:
var {
Icon,
} = require('react-native-icons');| 类别 | 图标数量 | 引用名 |
|---|---|---|
| FontAwesome 4.4 | 585 | fontawesome |
| ionicons 2.0.0 | 733 | ion |
| Foundation icons | 283 | foundation |
| Zocial | 99 | zocial |
| Material design icons | 744 | material |
我们在FontAwesome4.4网站上找了一个apple图标:

怎么用呢?看下面代码:
'use strict';
var React = require('react-native');
var {
Icon,
} = require('react-native-icons');
var {
AppRegistry,
StyleSheet,
View,
} = React;
var TesterHome = React.createClass({
render() {
return ( < Icon name = 'fontawesome|apple'
size = {
150
}
style = {
styles.beer
}
/>
);
}
});
var styles = StyleSheet.create({
container: {
flex: 1,
},
beer: {
width: 150,
height: 150,
}
});
AppRegistry.registerComponent('TesterHome', () => TesterHome);
核心代码是fontawesome|apple就是这么简单.所以的引用都是库名的引用名|图标的名称