1、备份文件
mv /usr/bin/systemctl /usr/bin/systemctl.old
2、下载systemctl文件
curl https://raw.githubusercontent.com/gdraheim/docker-systemctl-replacement/master/files/docker/systemctl.py > /usr/bin/systemctl
3、赋予权限
给脚本赋予执行权限
chmod +x /usr/bin/systemctl
1、备份文件
mv /usr/bin/systemctl /usr/bin/systemctl.old
2、下载systemctl文件
curl https://raw.githubusercontent.com/gdraheim/docker-systemctl-replacement/master/files/docker/systemctl.py > /usr/bin/systemctl
3、赋予权限
给脚本赋予执行权限
chmod +x /usr/bin/systemctl
function sleep(time){
return new Promise((resolve) => setTimeout(resolve, time));
}
async function route(
await sleep(15000);
}
route();
电脑生成公私钥
ssh-keygen -t rsa
将公钥加入git服务器
测试git是否连接成功
ssh -T git@githup.com -p port
正常使用就可以了
1.下载
百度网盘下载
链接:https://pan.baidu.com/s/18c5smZPzbk0ClhEYh4LQ2w
提取码:w7i8
2.安装
最近版本新出的镜像官方的 EFI 文件在虚拟机上部署有问题,如发现不能在虚拟机内使用,切换虚拟机配置为 BIOS,而非 UEFI 属性。
3.激活
首先输入下面的命令,更改Windows server 2022操作系统序列号。
VDYBN-27WPP-V4HQT-9VMD4-VMK7H
slmgr -ipk VDYBN-27WPP-V4HQT-9VMD4-VMK7H
接下来更改KMS激活服务器,使用下面的命令进行更改
slmgr /skms kms.03k.org
完成KMS服务器的设置以后,就可以使用下面的命令来激活你的Windows server 2022操作系统。
slmgr -ato
通过slmgr.vbs -dlv命令可以看到激活后的使用期限为180天,可以重置的计数1000次以上,应该可以让你完成测试使用。以上的方法供学习使用。
1、iptables 端口转发
CentOS 7.0 以下使用的是iptables,可以通过iptables实现数据包的转发。
(1)开启数据转发功能
vi /etc/sysctl.conf #增加一行 net.ipv4.ip_forward=1 //使数据转发功能生效 sysctl -p
(2)将本地的端口转发到本机端口
iptables -t nat -A PREROUTING -p tcp --dport 2222 -j REDIRECT --to-port 22
(3)将本机的端口转发到其他机器
iptables -t nat -A PREROUTING -d 192.168.172.130 -p tcp --dport 8000 -j DNAT --to-destination 192.168.172.131:80 iptables -t nat -A POSTROUTING -d 192.168.172.131 -p tcp --dport 80 -j SNAT --to 192.168.172.130 #清空nat表的所有链 iptables -t nat -F PREROUTING
2、firewall 端口转发
CentOS 7.0以上使用的是firewall,通过命令行配置实现端口转发。
(1)开启伪装IP
firewall-cmd --permanent --add-masquerade
(2)配置端口转发,将到达本机的12345端口的访问转发到另一台服务器的22端口。
firewall-cmd --permanent --add-forward-port=port=12345:proto=tcp:toaddr=192.168.172.131:toport=22
(3)重新载入,使其生效。
firewall-cmd --reload
3、rinetd 端口转发
rinetd是一个轻量级TCP转发工具,简单配置就可以实现端口映射/转发/重定向。
(1)源码下载
wget https://li.nux.ro/download/nux/misc/el7/x86_64/rinetd-0.62-9.el7.nux.x86_64.rpm
(2)安装rinetd
rpm -ivh rinetd-0.62-9.el7.nux.x86_64.rpm
(3)编辑配置文件
vi rinetd.conf 0.0.0.0 1234 127.0.0.1 22
(4)启动转发
rinetd -c /etc/rinetd.conf
4、ncat 端口转发
netcat(简称nc)被誉为网络安全界的”瑞士军刀“,一个简单而有用的工具,这里介绍一种使用netcat实现端口转发的方法。
(1)安装ncat
yum install nmap-ncat -y
(2)监听本机 9876 端口,将数据转发到 192.168.172.131的 80 端口
ncat --sh-exec "ncat 192.168.172.131 80" -l 9876 --keep-open
5、socat 端口转发
socat是一个多功能的网络工具,使用socat进行端口转发。
(1)socat安装
yum install -y socat
(2)在本地监听12345端口,并将请求转发至192.168.172.131的22端口。
socat TCP4-LISTEN:12345,reuseaddr,fork TCP4:192.168.172.131:22
6、 portmap 端口转发
Linux 版的lcx,内网端口转发工具。
(1)下载地址:
http://www.vuln.cn/wp-content/uploads/2016/06/lcx_vuln.cn_.zip
(2)监听本地1234端口,转发给192.168.172.131的22端口
./portmap -m 1 -p1 1234 -h2 192.168.172.131 -p2 22
parseFloat((数学表达式).toFixed(digits)); // toFixed() 精度参数须在 0 与20 之间
// 运行
parseFloat((1.0 – 0.9).toFixed(10)) // 结果为 0.1
parseFloat((0.3 / 0.1).toFixed(10)) // 结果为 3
parseFloat((9.7 * 100).toFixed(10)) // 结果为 970
parseFloat((2.22 + 0.1).toFixed(10)) // 结果为 2.32
1.在下载好的tp5.0 框架里面使用 composer 下载phpexcel 的插件
composer require phpoffice/phpexcel
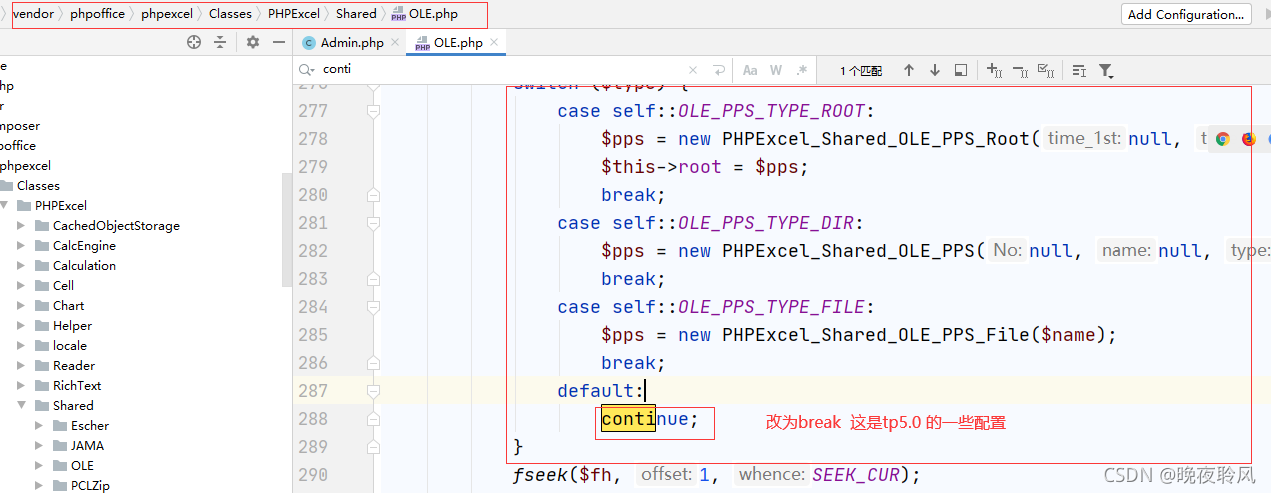
在下载好之后需要将/vendor/phpoffice/phpexcel/classes/phpexcel/ole.php 里面的continue 改为break;
2.在框架里面创建使用phpexcel 导出方法
引入相应的类
use PHPExcel_IOFactory;
use PHPExcel;
public function export()
{
//1.从数据库中取出数据
$list = Admins::where('login_status', 0)->order('id', 'desc')->column('id,username,phone,create_time');
$list = array_values($list);
//3.实例化PHPExcel类
$objPHPExcel = new \PHPExcel();
//4.激活当前的sheet表
$objPHPExcel->setActiveSheetIndex(0);
//5.设置表格头(即excel表格的第一行)
$objPHPExcel->setActiveSheetIndex(0)->setCellValue('A1', 'ID')->setCellValue('B1', '用户名')->setCellValue('C1', '手机号码')->setCellValue('D1', '创建时间');
//设置B列水平居中
$objPHPExcel->setActiveSheetIndex(0)->getStyle('B')->getAlignment()->setHorizontal(\PHPExcel_Style_Alignment::HORIZONTAL_CENTER);
//设置单元格宽度
$objPHPExcel->setActiveSheetIndex(0)->getColumnDimension('E')->setWidth(15);
$objPHPExcel->setActiveSheetIndex(0)->getColumnDimension('F')->setWidth(30);
//6.循环刚取出来的数组,将数据逐一添加到excel表格。
for($i=0;$i<count($list);$i++){
$objPHPExcel->getActiveSheet()->setCellValue('A'.($i+2),$list[$i]['id']);//添加ID
$objPHPExcel->getActiveSheet()->setCellValue('B'.($i+2),$list[$i]['username']);//添加用户名
$objPHPExcel->getActiveSheet()->setCellValue('C'.($i+2),$list[$i]['phone']);//添加手机号码
$objPHPExcel->getActiveSheet()->setCellValue('D'.($i+2),$list[$i]['create_time']);//添加创建时间
}
//7.设置保存的Excel表格名称
$filename = '管理员'.date('ymd',time()).'.xls';
//8.设置当前激活的sheet表格名称;
$objPHPExcel->getActiveSheet()->setTitle('管理员列表');
//9.设置浏览器窗口下载表格
header("Content-Type: application/force-download");
header("Content-Type: application/octet-stream");
header("Content-Type: application/download");
header('Content-Disposition:inline;filename="'.$filename.'"');
//生成excel文件
$objWriter = \PHPExcel_IOFactory::createWriter($objPHPExcel, 'Excel5');
//下载文件在浏览器窗口
$objWriter->save('php://output');
exit;
}
3.这里面的excel 的格式是定式的 ,如果表字段比较多的话可以创建数组循环设置
mysql配置文件将innodb_autoinc_lock_mode设置为0
穿透: pointer-events:none; 不穿透: pointer-events:auto;
执行 composer update 命令的时候报 Your requirements could not be resolved to an installable set of packages. 错误
Your requirements could not be resolved to an installable set of packages.
以上原因:不匹配composer.json要求的版本。
解决方案:
composer可以设置忽略版本匹配,
composer install –ignore-platform-reqs
composer update –ignore-platform-reqs
再次执行composer命令可以正常安装包了。
————————————————
版权声明:本文为CSDN博主「请叫我大稳哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35646802/article/details/103009912